TL;DR Internally CPython stores strings with fixed character size of 1, 2, or 4 bytes, depending on the string [PEP-393]. The indexing operator s[n] takes constant time. UTF-8 representation can be created via PyUnicode_AsUTF8()
During a discussion about Python internals, a question arose about how Python represents strings internally, and what is the time complexity of the index operator s[n]. The initial idea was that Python stores strings in UTF-8, which has variable character length. When encoded in UTF-8, ASCII characters take 1 byte, Greek, Cyrillic and other “small” alphabets take 2 bytes, Kanji and Devanagari take 3 bytes. Therefore, calculating nth character in an UTF-8 string is an O(n) operation: to calculate the offset of the nth character, one must scan the string from the beginning. Contrary to that, if each character has constant width, taking nth character is an O(1) operation: which just need to multiple the index by the character size to get the offset.
I asked Claude to generate a program that verifies the behavior of the indexing operator in Python which can be found at https://github.com/ikriv/python-string-access.
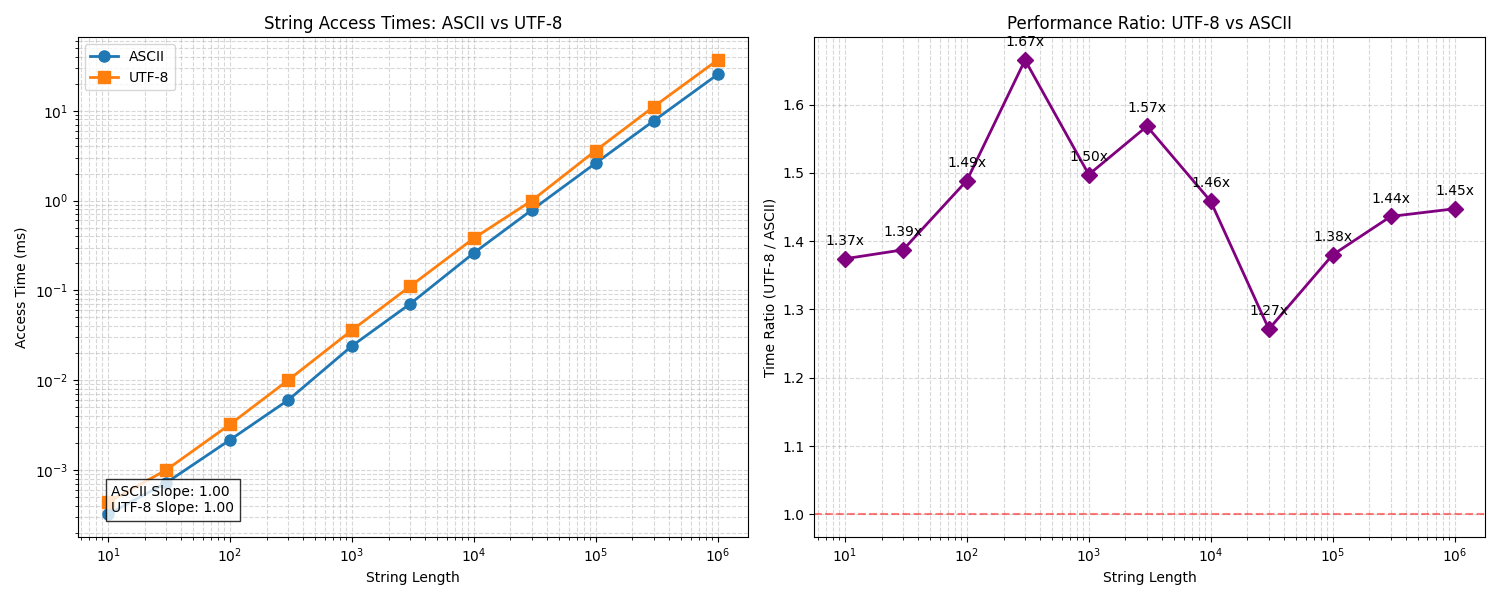
The result decisively shows that the indexing operator is constant time. The program loops through strings of increasing length and accesses every character in a string by index. If each character access is O(1), then the time to access all characters would be O(n), where n is the string length. On a log-log plot this corresponds to a straight line with a slope of 1.
“UTF8” here actually means “non ASCII” – a random combination of Latin, Cyrillic, Greek, and Hebrew characters. Python stores it as a string with characters size of 2 bytes.
Looking closely at Python’s string representation, we find that it stores two pointers: a union of 1-byte, 2-byte, or 4-byte character string, and an additional char* pointer that contains an optional UTF-8 representation of the string: code pointer. An additional optimization is that for ASCII strings UTF-8 representation and ASCII representation point to the same buffer, since UTF-8 representation of an ASCII string is the ASCII string itself.
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding the
* terminating \0. */
char *utf8; /* UTF-8 representation (null-terminated) */
} PyCompactUnicodeObject;
/* Object format for Unicode subclasses. */
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;
So, string element access is done via one of the fixed-width pointers, and is therefore constant time.