This Friday I wrote a unit test and to my astonishment I have found that “a” < “A” < “ab”, with .NET InvariantCulture and InvariantCultureIgnoreCase string comparers.
That means that .NET string sorting is not lexicographical, that came as a shock to me. If it were lexicographical, the order would have been “a” < “ab” < “A”.
If the strings differ by more than just case, both case sensitive and case insensitive comparers (except Ordinal, see below) will return the same result. Any of the strings in [“ab”, “aB”, “Ab”, “AB”] will be less than any of [“ac”, “aC”, “Ac”, “AC”].
For strings that differ only by case, insensitive comparers return “equal” and sensitive comparers maintain order, so you get “ab” < “aB” < “Ab” < “AB”.
This produces a “natural” sorting where “google” and “Google” are close to each other, but it is not lexicographical. Consider unsorted input “google, Google, human, zebra, Antwerp”. Lexicographically it would sort as “google, human, zebra, Antwerp, Google”, while most .NET comparers would sort it as “Antwerp, google, Google, human, zebra”.
StringComparer.Ordinal and StringCoparer.OrdinalIgnoreCase stand out: these two are truly lexicographical. Also, they put capitals before small letters, because this is the order in which they appear in UNICODE. I created a little application that sorts strings using various comparers:
https://github.com/ikriv-samples/DotNetStringSorting
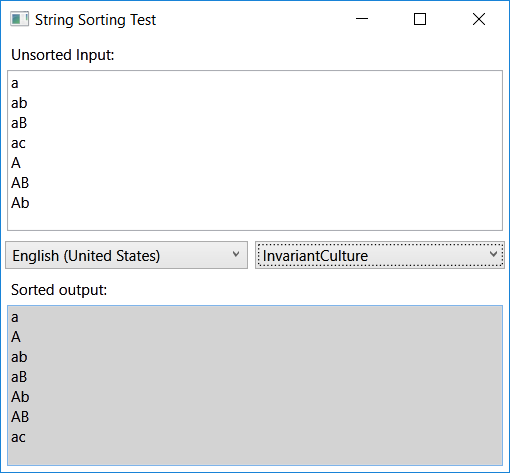
Input:
a, ab, aB, ac, A, AB, Ab
Sorted with StringComparer.InvariantCulture:
a, A, ab, aB, Ab, AB, ac
Sorted with StringComparer.InvariantCultureIgnoreCase:
a, A, ab, aB, AB, Ab, ac
Sorted with StringComparer.Ordinal:
A, AB, Ab, a, aB, ab, ac
StringComparer.OrdinalIgnoreCase:
a, A, ab, aB, AB, Ab, ac
The lesson learnt: never assume anything unless verified. I’ve been working with .NET for over 10 years, and I never doubted that string comparison is lexicographical (what else could it possibly be?). I was up for a big surprise.